Data Ingestion Checklist: Your Blueprint for Reliable Data
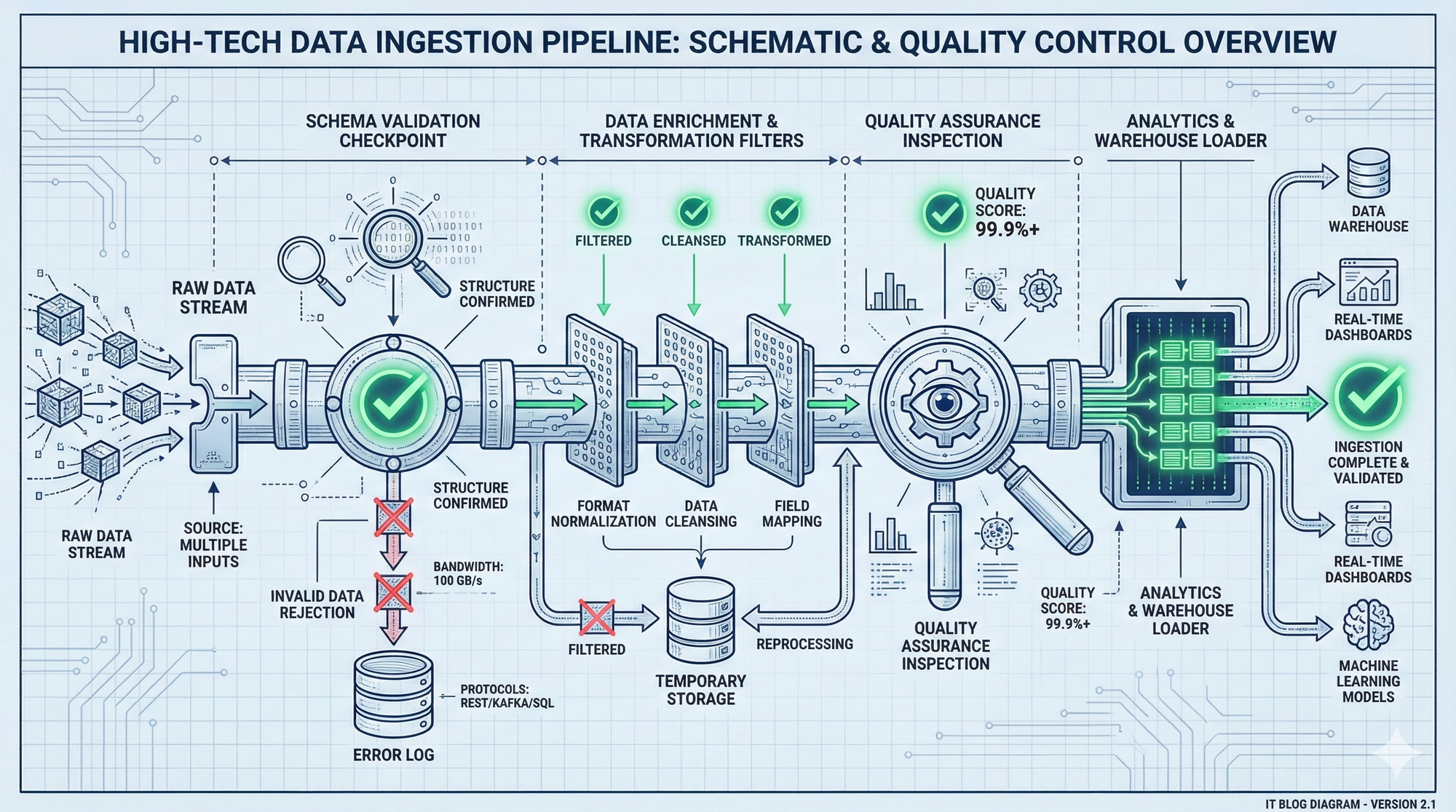
TL;DR: The Ingestion Safety Net
- The Problem: Messy data gets into your system, causing errors, bad reports, and distrust.
- The Solution: A structured, repeatable checklist for every new data source.
- Key Areas: Define the Source, understand the Data, build Quality Checks, and ensure Governance.
- The Big Win: Consistent, high-quality data that you (and your business) can actually trust.
From Chaos to Clarity: Why a Checklist Matters
In my previous post, I highlighted how critical Data Quality is for any modern IT infrastructure. But how do we achieve it? The first line of defense is at the ingestion point.
Every new data source, whether it's a legacy database, a new SaaS application, or a real-time stream, is a potential entry point for dirty data. Without a clear, step-by-step process, you're essentially letting data in "blind." That's why I've developed this checklist based on my experience. It’s designed to transform your data intake from a gamble into a controlled, reliable process.
The Muhammad Rizki DevLog Data Ingestion Checklist
This checklist is divided into four phases. Treat it like a pre-flight check for your data.
Phase 1: Source & Scope Definition
(Understand what you're ingesting and why)
- [ ] Identify Data Source: (e.g., CRM DB, IoT stream, HR Flat File)
- [ ] Define Business Purpose: What problem does this data solve? What decisions will it inform?
- [ ] Identify Data Owners/Stewards: Who is responsible for this data at the source?
- [ ] Volume & Velocity Assessment: (e.g., Gigabytes/day, millions of records/hour)
- [ ] Latency Requirements: How fresh does this data need to be? (e.g., real-time, daily batch)
Phase 2: Data Understanding & Profiling
(Get to know your data's DNA)
- [ ] Schema Discovery: Understand all tables, columns, and data types.
- [ ] Sample Data Review: Manually inspect a sample for anomalies.
- [ ] Data Profiling Report: Generate statistics (min/max, averages, null counts, unique values) using tools like Apache Atlas.
- [ ] Identify Sensitive Data (PII/PCI): Apply Apache Atlas tags (e.g.,
PII,GDPR_DATA). - [ ] Assess Data Granularity: What does one "row" represent? (e.g., a customer, a transaction, a sensor reading)
Phase 3: Quality Rules & Transformation
(Ensure data integrity before it enters the Lakehouse)
- [ ] Define Key Quality Expectations: (e.g.,
customer_idcannot be null,timestampmust be monotonic) - [ ] Implement Automated Quality Checks: Integrate frameworks like Great Expectations or custom Spark/SQL validation.
- [ ] Error Handling Strategy: What happens if a quality check fails? (e.g., quarantine, alert, reprocess)
- [ ] Data Cleansing/Standardization Rules: (e.g., standardizing addresses, converting date formats)
- [ ] Schema Evolution Strategy: How will changes in the source schema be handled? (e.g., schema registry, evolve-on-read)
Phase 4: Governance & Operationalization
(Make it secure, accessible, and sustainable)
- [ ] Security & Access Policies: Define Apache Ranger policies (resource, tag, ABAC) for who can access this data.
- [ ] Data Lineage Integration: Ensure Apache Atlas tracks the data's journey end-to-end.
- [ ] Monitoring & Alerting: Set up alerts for ingestion failures or significant data quality drifts.
- [ ] Documentation: Create clear documentation for the source, ingestion pipeline, and quality rules.
- [ ] Metadata Integration: Ensure all relevant metadata is captured in the CDP Data Catalog.
The "Rizki" Take: Your First Line of Defense
This checklist isn't just about technical steps; it's about building trust. By systematically addressing each point, we ensure that the data flowing into our systems is clean, reliable, and governed from the very start. It’s an investment that pays dividends in accurate reports, effective analytics, and confident business decisions.